Google GShard
Scaling Giant Models with Conditional Computation and Automatic Sharding
About Google GShard
Google has developed a system to increase the size of language translation models with the help of conditional computing and automatic sharding. The paper discusses the successful application of this system to a model of 600 billion parameters that was trained on 2048 TPU v3 cores.
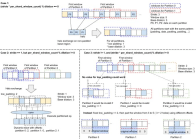
Scaling up neural networks has been a key factor in improving the quality of machine learning models. Despite the advantages of this approach, there are challenges, including computation costs, ease of programming, and efficient implementation on different devices. GShard is a module composed of a set of light annotation APIs and an extension to the XLA compiler. This system allows for a wide range of parallel computing patterns without requiring drastic changes to the existing model code. GShard enabled Google to scale up a multilingual translation model to more than 600 billion parameters using automatic sharding. The results showed that the model could be trained efficiently on 2048 TPU v3 accelerators in only four days, producing better quality translations for 100 languages to English than any previous model.
Read paper: https://arxiv.org/pdf/2006.16668.pdf