Chinese LLaMA & Alpaca LLMs
About Chinese LLaMA & Alpaca LLMs
Recently, there has been an increasing interest in the field of natural language processing due to the development of Large Language Models (LLM), such as ChatGPT, GPT-4, etc. LLM has shown its potential in achieving general artificial intelligence (AGI). However, the resource-consuming nature of these models has posed certain challenges to the open academic research.
This project focuses on:
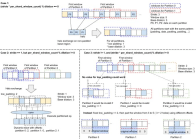
- ? Enhancing the Chinese vocabulary of the original LLaMA model, improving the efficiency of Chinese encoding and decoding
- ? Making the Chinese LLaMA large model (7B, 13B) pre-trained using Chinese text data open source
- ? Making the Chinese Alpaca large model (7B, 13B) that has been further fine-tuned by instructions open source
- ? Enabling people to deploy the quantized version of the model locally, and experience it on their laptop (personal PC)
- ? The image below illustrates the actual experience after the localized deployment of the 7B version model (animation is not accelerated, measured on Apple M1 Max).
Disclaimer: The resources related to this project are intended for academic research use only.
Chinese LLaMA & Alpaca LLMs screenshots